
What do we optimise first of all when we are talking about performance? That part that works with data storage. We can use key-value storage in RAM (Memcache or Redis) for some data but main data we keep in SQL database. Time of receiving data from memory is less than from the disk. It would be great to keep all data in RAM, wouldn’t it?
Fortunately there is such database - MemSQL.
MemSQL works with data in RAM and is a MySQL compatible database. It promises great speed in familiar LAMP stack. Is it so wonderful to be true? Let’s understand how it can be integrated with Drupal and when it can be used effectively.
Expectations and reality.
When we hear “in-memory database” (IMDB) we expect that disks aren’t used as data storage and data can be lost after server reboot. Also we think that it has to work super fast as data is in the memory.
In reality disks are used to store data and we can be calm for the data safety if database is rebooted.
In-memory databases are a new trend in keeping data as memory becomes cheaper every year. They are fitted very well to modern hardware. For example, IMDB writes data to the disks consistently using all advantages of SSD disks. All modern in-memory databases use distributed architecture therefore it is easy to build and scale clusters with lots of servers. Unfortunately IMDBs don’t resolve all issues with performance. Bottlenecks moved from the disk storage to other parts of a system.
Storage methods
Modern databases can be splitted on the operational and analytical. First type is used for operations accounting (Online Transaction Processing - OLTP) and stores data by row. Second type - for data analysis. It stores data by column.
MemSQL allows to store data by row and by column, moreover in the same database. Let’s have a look on the features of these two storing systems in MemSQL:
| Column store (OLAP) | Row store (OLTP) |
|---|---|
| Data is stored on the disk. Data is read from the disk. | Data is stored on the disk but then loaded to the RAM where it is read from. |
| Data is rarely updated. Main operation is reading. | Data is updated frequently and at random. |
| Works effectively with reading of big amount of consistent data. | Fast search of arbitrary data. |
| One index per table. | Few indexes are possible. |
| Data is compressed. Less amount of storage is needed than source data especially with pre-sorting. | Data is stored as-is. More space is needed for storage than source data. |
Column tables are defined by key CLUSTERED COLUMNSTORE. |
Architecture
MemSQL can work with a huge amount of data. But there isn’t RAM that can store more than a few hundred gigabytes. Therefore MemSQL cluster consists of a few parts - aggregators and leaves.
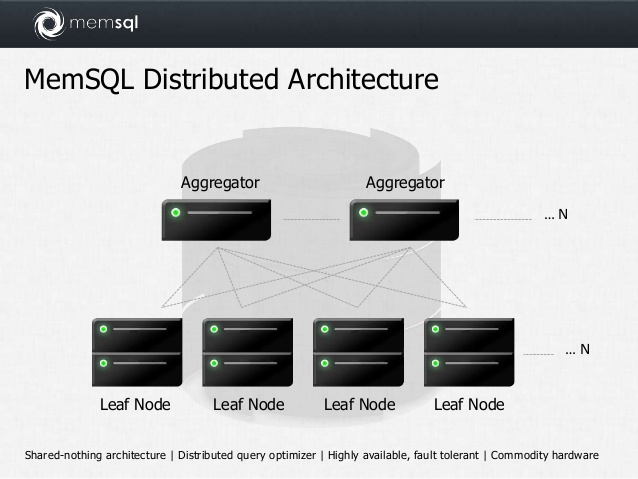
Aggregator stores information about leaves in a cluster. Leaves are used for storing data. All calculations take place here. MemSQL shares data across leaves automatically based on the Shard key.
Aggregator calculates hash value of the Shard key index and sends row to store on the leave based on this hash value.
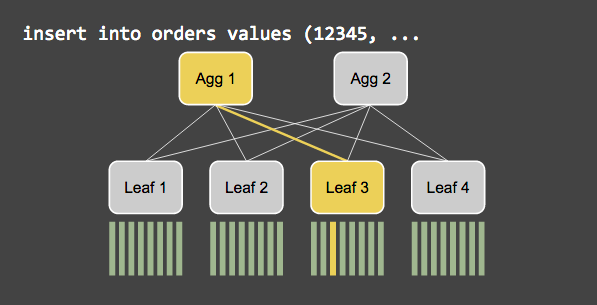
In the read operation aggregator sends request to the leaves. Then it combines requested data from the leaves and returns it to the client.

It’s quite simple to add aggregators and leaves and, thus, scale data storage.
Durability
Can we rely on the database that stores data in memory? Don’t we lose data after server reboot?
MemSQL developers insist that this database is absolutely reliable and data isn’t lost. Transactions are added to the transaction log on the disk, compressed and saved to the database. System can be absolutely durable when all transactions are saved on the disk immediately. But performance can be increased at the expense of reliability and set transaction buffer that will be used to store transaction prior to sending to the disc. In this case the latest transaction can be lost but we will get better performance due to less number of disk requests.
Data is loaded from the disk and is merged with transactions from transaction log after server loads. It takes some time due to the performance of the file system.

System requirements
Host for MemSQL has to have at least 4 core CPU and 8 GB RAM. It is recommended to use Linux core not less 3.10. RHEL/CentOS 6 or 7, Debian 8 or 9 are supported now. I’ve used Ubuntu 18.04 for testing and it works good. MemSQL can be used in Windows using Docker container.
Is it payable?
MemSQL is a commercial database. But it can be used for free. Company uses concept “unit” to calculate price. Unit is a combination of memory and computing on the server. One unit is 8 vCPU and 32GB RAM. Four units cluster can be used for free.
Links: