
Что мы оптимизируем в первую очередь когда речь заходит о производительности Drupal? Ту часть, которая работает с хранилищем данных. Мы можем использовать key-value хранилище в ОЗУ (Memcache или Redis) для некоторых данных, но основные данные нам приходится хранить в SQL базе данных. Время получения данных из базы данных, которая находится на жестком диске, намного больше, чем из базы, которая находится в памяти. Было бы здорово, чтобы все данные были бы в оперативной памяти, не правда ли?
К счастью, такая база данных есть - MemSQL.
MemSQL работает с данными, которые находятся в памяти и, в тоже время, является MySQL совместимой базой данных. Это обещает нам превосходную скорость в привычном нам LAMP стеке. Слишком хорошо, чтобы быть правдой? Давайте разберемся как можно интегрировать Drupal c MemSQL и когда это может быть эффективно использовано.
Ожидания и реальность.
Когда мы слышим “in-memory database”, то складывается впечатление, что диски не используются для хранения данных, данные могут быть утеряны после перезагрузки сервера и это работает супер быстро, раз данные находятся в памяти.
Реальность же такова, что хоть данные и находятся в памяти, но диски используются для долгосрочного хранения данных. И мы можем не бояться за сохранность данных при перезагрузке базы данных.
In-memory базы это новый тренд в хранении данных, т.к. память становится дешевле с каждым годом. Они хорошо приспособлены к современному аппаратному обеспечению. Например, они записывают данные на диск последовательно, к чему очень хорошо приспособлены SSD диски. Современные in-memory базы данных используют распределенную архитектуру и поэтому довольно просто построить и расширять кластер с большим количеством серверов. Но, к сожалению, они не решают всех проблем с производительностью. Узкие места переместились с хранилища данных в другие части системы.
Способы хранения данных.
Современные базы данных можно разделить на операционные и аналитические. Первый тип баз данных используется для учета операций (On Line Transaction Processing - OLTP) и использует построчное хранение данных. Второй тип - для анализа данных (On Line Analytical Processing - OLAP). Здесь используется колоночное хранение.
MemSQL позволяет хранить данные как построчно, так и поколоночно, причем в одной базе данных. Давайте рассмотрим особенности работы этих двух систем в MemSQL:
| Колоночное хранение (OLAP) | Построчное хранение (OLTP) |
|---|---|
| Хранение данных на жестком диске. Считывание данных с жесткого диска. | Данные хранятся на жестком диске, но затем данные загружаются в оперативную память откуда потом и берутся. |
| Эффективно, когда данные обновляются редко. Основная операция - чтение. | Позволяет обновлять данные часто и в произвольном порядке. |
| Лучше справляется с чтением больших последовательных массивов данных. | Быстрый поиск произвольных данных. |
| Индекс по одному полю. | Возможно большое количество индексов. |
| Данные сжимаются. Данные занимают меньше места чем изначальные данные, особенно при предварительной сортировке. | Данные хранятся “как есть”. Данные в базе занимают в несколько раз больше места, чем изначальные данные. |
Колоночные таблицы определяются ключом с обозначением CLUSTERED COLUMNSTORE. |
Архитектура
MemSQL может работать с огромными массивами данных. Но пока еще нет ОЗУ которая могла бы хранить больше нескольких сотен гигабайт данных. Поэтому кластер MemSQL состоит из нескольких частей - агрегатор (aggregator) и листья (leaf).
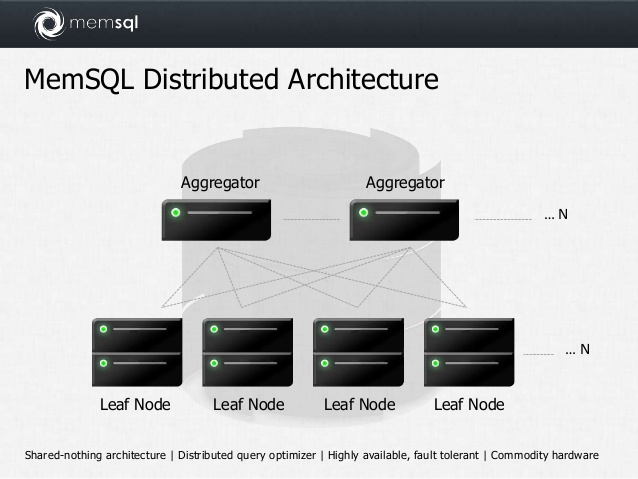
Агрегатор хранит информацию о листьях в кластере. Листья используются для хранения данных. Все вычисления происходят именно здесь. MemSQL автоматически распределяет данные между узлами.
При операции записи агрегатор вычисляет хеш у индекса SHARD KEY и сохраняет строку на leaf в соответствии со значением хеша.
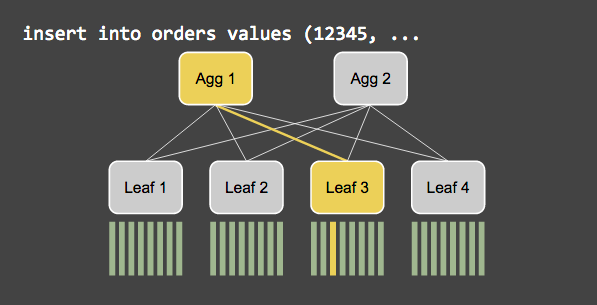
Получив sql запрос на чтение агрегатор отправляет этот запрос листьям. Затем он собирает полученные данные и отдает их клиенту.

В MemSQL достаточно просто добавлять агрегаторы и листья и, таким образом, масштабировать систему хранения данных.
Надежность
Когда мы говорим о том, что данные хранятся в памяти, то можем ли рассчитывать что данные у нас не потеряются при перезагрузке системы?
Разработчики MemSQL утверждают, что данные не потеряются. Транзакции фиксируются в журнале транзакций на диске, а затем сжимаются и сохраняются в базу данных. Есть возможность настроить абсолютно надежную систему, когда все транзакции будут попадать на жесткий диск сразу же. Возможно увеличить производительность за счет надежности и установить размер буфера транзакций при достижении которого данные будут отправляться на диск. В таком случае мы можем потерять последние транзакции, но зато выиграем в производительности за счет меньшего количества обращения к дискам.
При перезагрузке системы данные выгружаются из базы данных и берутся транзакции из журнала транзакций, которые еще не попали в базу. Так восстанавливается целостность после перезагрузки. На это уходит какое-то время потому, что тут MemSQL упирается в производительность файловой системы.

Системные требования
Хост для MemSQL должен иметь как минимум 4 ядра CPU и 8 GB RAM. Рекомендуется использовать ядро Linux не ниже 3.10. Поддерживаются RHEL/CentOS 6 или 7, Debian 8 или 9. Я для тестов использовал Ubuntu 18.04 на котором все работало замечательно. На Windows можно использовать MemSQL используя Docker контейнер.
Это платно?
MemSQL это платная база данных. Но можно использовать её бесплатно. Для определения стоимости компания использует понятие юнит. Юнит это сочетание вычислительной мощности и памяти на сервере. Один юнит это 8 vCPU и 32GB ОЗУ. Кластер на 4 юнита можно использовать бесплатно.
Ссылки: